- Published on
비관적 동시성 관리(2PL)
- Authors
- Name
- Intro
- Name
- 이상현상
- Name
- 비관적 동시성 관리: 2PL
- Name
- Strcit 2PL
- Name
- Deadlock Detection
- Name
- Deadlock Avoid
- Name
- 격리성 수준과 단계별 락
Tags
Previous Article
Intro
트랜잭션의 ACID 성질에서 격리성(Isolation)은 커밋되지 않은 트랜잭션에 의한 상태변경이 다른 트랜잭션에 관측되지 않는 성질을 의미한다.
이러한 격리성을 보장하는 가장 간단한 방법은 모든 트랜잭션이 순차적으로 실행되도록 하는 것인데, 이는 당연히 비효율적인 방법이다.
이를 위해 DBMS는 다양한 방법을 통해 동시에 여러 트랜잭션이 실행되면서도 서로 다른 트랜잭션이 격리된 환경에서 실행되도록 동시성을 보장한다.
트랜잭션이 동시에 실행될 때, 생길 수 있는 위험은 무엇일까? 먼저 바이트 레벨에서 데이터의 포맷이나 정합성이 망가질 수 있다.
하지만 이러한 위험은 보통 mutex나 spinlock 등의 저수준의 잠금을 통해 쉽게 해결할 수 있다.
우리가 초점을 맞추려는 부분은 트랜잭션의 격리성이 깨지는 부분이다. 트랜잭션의 격리성이 망가져, 관측되어서는 안될 데이터가 관측되는 현상을 우리는 "이상현상"이라고 부른다.
이상현상은 몇 가지 종류가 있는데, 둘 이상의 트랜잭션이 같은 범위에 속한 데이터를 다루고, 최소 하나 이상의 트랜잭션이 쓰기 작업을 수행할 때 잠재적으로 발생하게 된다.
이상현상
Non-Repeatable Read
Non-Repeatable Read는 한 트랜잭션이 똑같은 데이터를 여러번 읽을 때 발생할 수 있는 이상현상이다. 격리성이 보장되기 위해선 트랜잭션 자기 자신이 데이터를 변경하지 않는 이상, 항상 같은 상태를 관측해야만 한다. 만약 중간에 다른 트랜잭션에 의해 데이터가 변경되고 그러한 변경 상태로 인해 다른 값을 관측할 때 Non-Repeatable Read 현상이 발생한다고 얘기한다.
-- Transaction A
SELECT X FROM table WHERE id = 10; -- X = 100
SELECT X FROM table WHERE id = 10; -- X = 120
-- Transaction B
UPDATE table SET X = X + 20 WHERE id = 10;
Dirty Read
트랜잭션이 읽는 데이터의 상태는 반드시 커밋된(=데이터베이스에 영구적으로 반영된) 상태여야만 한다. 만약 커밋되지 않은 데이터 상태를 읽을 경우 그러한 상태가 롤백된다면 정상적인 읽기 작업이 보장될 수 없을 것이다. 이러한 상황을 보고 Dirty Read라고 얘기한다.
-- Transaction A
BEGIN
SELECT X FROM table WHERE id = 10; -- X = 120
-- Transaction B
BEGIN
UPDATE table SET X = X + 20 WHERE id = 10;
ROLLBACK -- X = 100
Lost Update
둘 이상의 트랜잭션이 어떤 데이터에 쓰기 작업을 수행 중이라 가정해보자. 예를 들어 트랜잭션 A은 데이터 X에 10을 더하고(X=X+10) B는 20을 더한다(X=X+20). 정상적인 동작이라면, 최종적으로 A, B가 커밋되었을 때 X는 X+30이 되어야 하지만, 동시에 쓰기 작업을 하며 둘 중 한 작업이 소실되어 X+10 혹은 X+20만 남아버린다. 이런 경우를 보고 변경작업이 비정상적으로 소실되었다 하여 Lost Update라고 한다.
-- Transaction A
BEGIN
UPDATE table SET X = X + 10 WHERE id = 10;
COMMIT -- X = 130?
-- Transaction B
BEGIN
UPDATE table SET X = X + 20 WHERE id = 10;
COMMIT -- X = 130?
Phantom Read
Full table scan 작업을 여러 번 수행한다고 가정하자. 마찬가지로 매 작업마다 같은 결과를 출력해야 한다. Phantom Read는 Non-Repeatable Read와 비슷하지만, 없던 데이터가 추가되는 현상이란 점에서 다르다.
-- Transaction A
SELECT COUNT(*) FROM table; -- count(*) = 100
SELECT COUNT(*) FROM table; -- count(*) = 101
-- Transaction B
INSERT INTO table VALUES (...);
Write Skew
Write Skew는 Lost Update와 비슷한듯 미묘하게 다른 이상현상이다. 서로 다른 트랜잭션이 데이터에 쓰기 작업을 진행하는데, 쓰기 작업 자체에선 충돌이 일어나지 않지만 결과적으론 의도치 않은 결과를 얻게 된다.
table(X int) = [0, 1, 0, 1, 0, 1, 0, 1]
-- Transaction A
UPDATE table SET X = X + 1 WHERE X = 0;
-- expect: table(X int) = [1, 1, 1, 1, 1, 1, 1, 1]
-- Transaction B
UPDATE table SET X = X - 1 WHERE X = 1;
-- expect: table(X int) = [0, 0, 0, 0, 0, 0, 0, 0]
최종적으로 정상적인 변경작업이라면, A->B 순서 혹은 B->A 순서로 진행되어 테이블 데이터는 모두 0 혹은 1이어야 하지만 결과적으론 0과 1을 뒤바꾼 테이블이 된다.
table(X int) = [1, 0, 1, 0, 1, 0, 1, 0]
비관적 동시성 관리: 2PL
**2PL(2-Phase Locking Protocol)**은 비관적인 동시성 관리 기법으로써 잠금(Lock)을 통해 동시적인 데이터 접근을 제어한다.
비관적이란 말의 의미는 항상 트랜잭션 간에 충돌이 일어나리라 가정한다는 것이다. 즉, 둘 이상의 트랜잭션이 언제든 동일한 데이터에 대해 접근하고 그 중 최소 한 트랜잭션은 쓰기 작업을 진행할 수 있다고 가정하는 것이다.
2PL은 이름에서 알 수 있듯 2단계에 걸쳐 잠금의 획득과 해제를 관리하는데, 이는 트랜잭션의 생애주기에 걸쳐 자원을 관리해야 하기 때문이다.
첫 번째 단계는 확장(Growing) 단계이다. 확장 단계에서는 임의의 잠금을 획득하는 것이 허용되며 이 때 이미 다른 트랜잭션이 잠금을 보유하고 있을 경우 대기(Block)해야 한다.
만약 하나의 락이라도 잠금을 해제할 경우 트랜잭션은 수축(Shrinking) 단계로 진입한다. 이 때부턴 트랜잭션은 새로운 잠금을 획득하는 것이 제한되며, 더 이상 필요없는 잠금을 해제하는 것만이 허용된다.
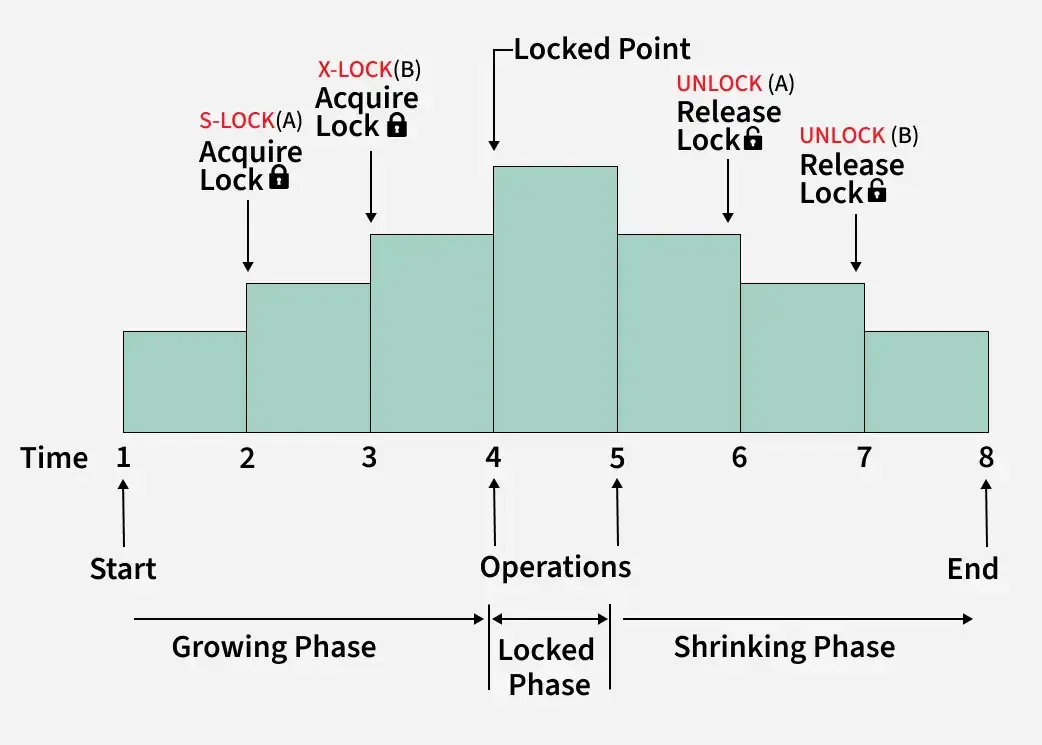
2PL의 핵심은 트랜잭션 간의 충돌 가능성을 제거하고, 모든 작업의 순서가 직렬화 가능(Serializable)하도록 제약을 부여하는 것이다. 무슨 말인가 하면, 트랜잭션 A와 B가 각각의 작업을 실시간으로 수행했을 때, 모든 작업 순서의 결과는 A->B 혹은 B->A 순서로 실행한 것과 동일해야 한다는 것이다.
이상현상을 모두 잘 살펴보면 본질적으론 작업 순서가 A->B도 아니고, B->A로도 치환할 수 없어 발생하는 문제임을 알 수 있다.
확장과 수축 단계를 통해 적어도 어떤 트랜잭션이 일련의 작업들을 수행했을 때, 다른 어떤 트랜잭션이 동일한 데이터에 대해 중간에 끼어들 수 없도록 제한됨으로써 격리성이 보장한다.
그럼 2PL은 만능일까? 아직 문제가 남아있다.
연쇄적인 롤백(Cascading Abort)과 Dirty Read
먼저 연쇄적인 롤백 문제가 있다. 2PL을 통해 안전한 격리성이 보장되는 것은 어디까지나 모든 작업이 안전하게 완료되어 커밋된다는 가정일 때 얘기이다. 다음 실행순서를 살펴보자.
-- Transaction A BEGIN SELECT * from table WHERE id = 10 FOR UPDATE -- X-lock id=10 UPDATE table SET X = X + 1 WHERE id = 10 -- unlock id = 10 ROLLBACK -- ?-- Transaction B BEGIN UPDATE table SET X = X - 1 WHERE id = 10 -- X-lock id = 102PL에 의하면 B는 정상적으로 id=10에 대한 X-lock을 획득하고 자신의 작업을 수행 중이지만, A가 롤백되었다. 롤백이라면, A가 실행되기 전의 상태로 돌아가야 하는데 그냥 'X = X - 1'만 계산하고 끝내면 될까? 이 경우야 '차이'란 개념이 존재해서 그나마 그럴듯하지만, 만약 text를 단순히 바꾸는 연산이었다면? 이런 저런 이유로 결국 A의 롤백으로 인해 B도 함께 롤백해야만 안전하게 데이터베이스의 일관성을 유지할 수 있다.
A의 커밋되지 않은 데이터에 B가 의존하면서 생기는 문제이다.
이미 락을 해제했는데 다시 롤백하려면.. 또 다시 락을 획득해야 할텐데. 이러면 2PL에 위반되지 않나? 좀 곤란하다.데드락 문제
기본적으로 2PL은 트랜잭션의 실제 작업 순서에 관해 아무런 제약을 정의하지 않는다. 사용자 레벨에서 발생하게 되는 경합상황과 데드락에 대한 해결법이 필요하다.
Strcit 2PL
첫 번째 문제를 해결하는 방법은 꽤 간단해보이기도 하는데, 아예 락의 해제를 트랜잭션의 완료시점까지 지연하는 것이다. Strict란 단어를 통해 규칙이 좀 더 엄격해졌음을 알 수 있다.
이를 통해 Dirty Read 문제를 확실하게 해결할 수 있다. Dirty Read가 불가하니 연쇄적인 롤백도 해결할 수 있다. 이러한 이점으로 인해 DBMS에서는 실질적으로 2PL을 적용할 때 Strict 2PL을 적용하며,
보통 격리성 레벨에 따라 2PL을 적용할 락 레벨(X, IX 등)을 변화시키고 나머지 락(S, IS 등)은 아예 2PL 규칙에서 제외시키는 식으로 구현한다.
2번째 문제인 데드락 문제의 경우 2PL을 개량하는 것이 아니라 아예 데드락을 방지할 수 있는 알고리즘을 추가적으로 적용하여 해결한다.
데드락은 보통 1. 백그라운드 스레드를 이용한 탐지(Detection) 방식과 2. 트랜잭션의 우선 순위를 이용한 회피(Avoid) 방식을 이용한다.
Deadlock Detection
데드락 탐지의 경우 waits-for graph를 주로 이용한다. waits-for는 트랜잭션의 대기 관계를 표현하는 방향 그래프로, 만약 B가 A가 소유한 락을 대기 중일 경우 B->A로 엣지가 그려진다.
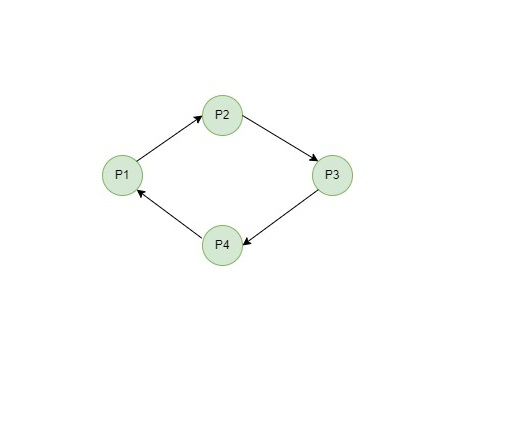
이제 데드락 탐지는 DFS 방식으로 사이클을 찾아 이루어지며, 백그라운드 스레드를 통해 일정 주기를 두고 탐지하여 보통 제일 나중에 생성된 트랜잭션을 취소(Abort, Rollback)하는 방식이다.
Deadlock Avoid
데드락 회피의 경우 아예 순환 의존 관계가 발생할 가능성 자체를 차단한다는 점에서 좀 다르다. 트랜잭션이 락을 요청하는 시점에 우선순위에 따라 대기할지, 아니면 취소할지, 강제로 점유권을 뺏어올지 등을 결정해버리는데 보통 다음의 규칙에 따라 수행한다.
Wait-Die
만약 새롭게 락을 요청하는 트랜잭션이 점유 중인 트랜잭션보다 우선순위가 높을 경우 대기하고, 그렇지 않으면 작업을 취소한다.Wound-Wait
만약 새롭게 락을 요청하는 트랜잭션이 점유 중인 트랜잭션보다 우선순위가 높을 경우 점유 중인 트랜잭션을 취소하고, 그렇지 않으면 대기한다.
두 방식 모두 결국은 낮은 우선순위의 대기만 허용 혹은 높은 우선순위의 대기만 허용하여 근본적인 순환 관계를 아예 막아버린다는 점이 핵심이다.
일반적으로 DBMS는 첫번째 방식(=데드락 탐지)를 이용하는데, 가장 큰 이유는 불필요한 트랜젝션을 취소하는 것보다 실제 데드락이 발생했을 때에만 취소할 수 있기 때문이다.
격리성 수준과 단계별 락
격리성 수준(Isolation Level)은 DBMS가 "읽기 작업"에 대해 얼마나 엄격하게 격리성을 보장할지에 대해 결정한다. 낮은 레벨일수록 느슨한 격리성을 가지지만 일관성이 깨진 상태를 읽을 가능성이 높고, 높은 레벨일 수록 엄격한 격리성을 통해 안정적인 데이터베이스 상태를 읽을 수 있다. SQL 표준에 의하면 보통 4단계로 구분하는데 다음과 같다.
READ UNCOMMITTED
가장 느슨한 단계로 격리성에 대해 그 어떤 것도 보장하지 않는다. 이름에서 알 수 있듯 커밋되지 않은 데이터를 임의로 읽을 수 있다. 다만 이는 앞서 말했듯이 읽기 작업에 해당하는 것으로 쓰기 작업 자체는 보통 안전하게 수행한다. 다만 쓰기 작업이 읽기 작업에 의존할 경우 안전한 작업이 보장되지 않는다. 따라서 읽기 작업의 일관성보다 빠른 접근이 더 중요할 경우에만 적합하다.
READ COMMITTED
커밋된 데이터에 대해서만 읽기를 보장한다. 따라서 적어도 데이터베이스에 영구적으로 반영된 사항에 대해서만 읽을 수 있음이 보장되지만, 트랜잭션이 진행되는 도중에서 실시간으로 커밋된 데이터에 의해 데이터베이스 상태가 변화할 수 있기 때문에 반복적인 읽기에서 일관성이 꺠질 수 있다.
REPEATABLE READ
READ COMMITTED 수준의 격리성 보장은 물론 반복적인 읽기를 보장한다. 다만 새로운 데이터의 추가(INSERT)를 막지는 않기 때문에 유령읽기(Phantom Read)를 막아주진 않는다.
SERIALIZABLE
REPEATABLE READ 수준의 격리성 보장 + 유령 읽기(Phantom Read)를 예방한다. 가장 엄격한 수준이기 때문에 안정적인 데이터베이스 상태가 꼭 필요할 경우에만 사용한다.
DBMS는 또한 세분화된 잠금 수준과 범위를 통해 트랜잭션의 작업 범위를 최대한 정밀하게 제어하는데, 이는 당연히 가능한 많은 트랜잭션이 데이터에 접근할 수 있도록 허용하기 위함이다.
보통 잠금의 범위는 데이터베이스, 테이블, 페이지, 튜플에 따라 구분하며 극단적일 경우 튜플의 컬럼 단위로도 보호할 수 있다. 인덱스(B+-Tree)의 경우 키 범위를 이용해 갭락(Gap Lock)이라는 종류의 락을 사용하기도 한다.
잠금의 수준의 경우 S-Lock과 X-Lock 뿐만 아니라 Intention이란 키워드를 통해 세분화된다.
Shared <-> Intention Shared
Intention Shared는 하위 노드(튜플)을 읽겠다는 의미로 상위노드(테이블)에 적용하는 잠금이다. Shared는 해당 노드 자체를 직접적으로 수정하겠다는 의미로 보통 튜플(혹은 컬럼) 단위에서만 수행하고, 테이블에서는 DDL을 수행하는 경우가 아니라면 대부분의 상황에 Intention Lock을 건다. 다만 높은 격리수준(Serializable)에서는 Phantom Read를 방지하기 위해 table scan이나 index range scan 등을 수행할 때 테이블 전체에 Shared Lockd을 걸기도 한다.
eXclusive <-> Intention eXclusive
똑같은 의미를 베타적 잠금에 적용했다고 보면 된다.
Shared Intention eXclusive
테이블 전체를 읽되 특정 튜플에 대해 쓰기 작업을 수행하겠단 의미이다. 예컨데 Non-index key를 통해 특정 조건을 만족하는 튜플들을 찾아 변경하는 경우가 있다. 전체 테이블을 읽긴 하지만, 특정 튜플에 대해서만 변경하고자 할 경우 사용한다.
각 잠금의 호환성은 다음과 같다.
| IS | IX | S | SIX | X | |
|---|---|---|---|---|---|
| IS | O | O | O | O | |
| IX | O | O | |||
| S | O | O | |||
| SIX | O | ||||
| X |
이제 어떤 식으로 격리 수준을 보장할지 생각해보자.
READ UNCOMMITTED의 경우 쓰기 작업에서 X, IX 외에는 아무런 잠금도 사용하지 않는다. 물론 수축(Shrinking) 단계에서는 새로운 잠금이 허용되지 않는다.
그럼 READ COMMITTED는? 모든 잠금을 허용하되 수축 단계에선 S와 IS 타입만 허용한다. 다르게 생각하면, S나 IS 타입은 사용 직후 즉시 해제하여 다른 접근을 허용한다.
REPEATABLE READ의 경우 모든 잠금 타입(IS, IX, S, SIX, X)에 대해 2PL을 적용한다. 즉, 수축 단계에서는 어떠한 타입의 잠금도 허용하지 않으며, S와 IS 또한 트랜잭션이 종료될 때까지 유지해야만 한다.
SERIALIZABLE의 경우 REPEATABLE READ와 동일하되, table scan에서 IS 타입이 아니라 S 타입을 통해 테이블 전체를 보호한다.