- Published on
데이터베이스의 메모리 관리 전략
- Authors
- Name
- Intro
- Name
- Buffer Pool
- Name
- 다 사용한 메모리 관리 전략?
- Name
- FIFO vs LFU vs LRU
- Name
- InnoDB의 개량 LRU 알고리즘
- Name
- 왜 이런 방식을??
Tags
Previous Article
Next Article
Intro
RDBMS는 데이터의 효율적인 접근, 즉, 디스크 IO 작업 시간을 줄이기 위해 인메모리 자료구조를 통해 캐싱을 수행한다.
따라서 RDBMS의 데이터 저장은 In-Memory Structure와 On-Disk Structure로 나뉘어 구성되며
오늘은 In-Memory Structure의 일부인 Buffer Pool에 대해서 공부할 것이다.
Buffer Pool
RDBMS는 메모리를 통해 디스크의 데이터를 임시저장하여 읽기/쓰기 작업 전반을 관리한다.
이러한 요구사항을 위해 먼저 고려해야할 것은 무엇일까?
가장 첫번째는 메모리 공간의 희소성?이다.
방대한 양의 데이터를 저장할 수 있는 디스크에 비하면, 메모리 공간이 매우 귀한 자원임은 우리가 이미 알고 있다.
우연찮게 메모리 공간과 디스크를 1대1로 맵핑할 수 있다면 참 좋으련만..
메모리 공간은 휘발적일 뿐만 아니라 용량 또한 그리 넉넉치가 않다.
버퍼풀(Buffer Pool)이란 용어를 사용하게 된 이유를 알 수 있다.
무한정 메모리를 사용할 수 없으니, 최대 상한선을 정해두고
그 안에서 메모리를 어찌저찌 재사용해야만 안전한 시스템을 구성할 수 있기 때문이다.
따라서 **자유로운 메모리 공간(Pool)**이 있을 경우 새로운 메모리를 할당하고
없을 경우 기존에 사용 중이던 메모리를 비워서(evict) 사용해야 한다.
다 사용한 메모리 관리 전략?
이제 여기서 두 가지 전략을 생각해볼 수 있다.
- 사용이 끝난 데이터는 즉시 메모리에서 해제
def access(page, task):
load(page)
task(page)
evict(page)
- 사용이 끝나더라도 데이터를 메모리에 유지
def access(page, task):
if page in memory:
task(page)
else:
load(page)
task(page)
1.은 매우 직관적이다. 메모리 공간이 부족하니 필요한 데이터만 적재하고 사용한 데이터는 바로 메모리에서 해제하는 것이다.
그러나 실제로는 거의 대부분 2.를 채택하는데, 이는 반복적인 데이터 접근을 효율적으로 수행하기 위함이다.
만약 모든 데이터가 균등한 확률로 접근된다면 1.의 설득력이 올라가겠지만, 절대다수의 시스템에서는 데이터들이 사용되는 비율이 균등하지 않다.
당장 유튜브같은 시스템만 생각해보더라도 구독자수, 인기급상승 등의 여부로 특정 영상은 엄청난 트래픽을 자랑할테지만 나같이 구독자수 0명이 아무 영상을 올린다면
한 10년 묵혀놔도 조회수 1000개 나온다.
따라서 사용이 끝났다고 해도 즉시 메모리에서 해제하기 보단, 어느정도 메모리에 유지하면서 반복적인 요청에 빠르게 대응하는 것이 더 효율적인 전략임은 자명하다.
그렇다면 2.를 위해 고려할 사항이 새로 추가된다. 바로 "어떤" 메모리를 "언제" 해제할 것인가이다.
어떤 데이터를 담은 메모리가 해제되어야 할까? 당연히 정답은 더 이상 사용되지 않을 확률이 높은 데이터가 되어야만 한다.
더 이상 사용되지 않을 데이터를 어떻게 구분할 수 있을까?
안타깝지만 절대적인 판단기준이란 존재하지 않는다. 우리는 미래를 정확히 예측할 수 없다.
따라서 우리는 어느정도 경험적(heuristic)인 판단기준을 통해 더 이상 사용되지 않을 데이터를 구분해야 한다.
즉, 어느정도의 설득력과 사용경험에 기반하여 판단해야만 한다는 것.
그럼 어떻게 해야 할까? 우리가 가진 것은 과거의 정보 밖에 없다.
어떤 정보를 가지고 판단해야 할까?
보통 근거로 하는 정보는 3가지이다.
- 메모리에 적재된지 얼마나 오래되었는가?(FIFO)
- 참조된 회수가 얼마나 적은가?(LFU)
- 마지막으로 참조된 시간이 얼마나 오래되었는가?(LRU)
FIFO vs LFU vs LRU
- FIFO(First In First Out)은 말그대로 가장 먼저 들어온 데이터를 가장 먼저 내보내는 자료구조이다.
앞서 말했듯 메모리에 적재된 시간경과가 가장 큰 데이터를 교체하자는 말이다.
이 주장은 쉽게 반박이 되는데, 오래되었다는 것이 더이상 필요없다는 것을 의미하지 않기 때문이다.
오히려 자주 사용되는 데이터는 당연히 오래 저장되어야만 한다. 간단히 Queue를 통해 구현할 수 있을 것이다.
buffer = [x1, x2, ..., x100]
def access(page, task):
if page not in buffer and full(buffer):
pop_front(buffer)
load(page) # push_back
task(page)
...
access(y, task)
# memory = [x2, ..., x100, y]
- LFU(Least Frequently Used)는 참조된 횟수가 가장 적은 데이터가 앞으로도 사용되지 않을 것이라는 가정을 따른 전략이다.
이 경우 크게 2가지 반박이 가능한데
첫 번째는 새롭게 참조된 데이터가 자주 사용될 가능성을 무시한다는 점이다.
치명적으로 보이는 두번째 반박은 구현이 아주 곤란하다는 점. 매번 참조된 횟수를 카운팅해야만 함은 물론, 매번 참조 횟수에 따라 정렬 하거나
페이지 교체마다 완전탐색을 하는 두 가지 방식을 생각해볼 수 있는데 그 오버헤드가 어마어마할 것이다.
시스템의 가장 기본적인 데이터 읽기/쓰기 작업을 과연 감당이 가능할까?
buffer = [x1, x2, ..., x100]
def access(page, task):
if page not in buffer and full(buffer):
minimum_accessed_page = null
for buffered_page in buffer:
...
evict(minimum_accessed_page)
load(page)
task(page)
page.access_time = 1
...
access(y, task)
# buffer = [x1, x2, ... , x31, y, x32, ..., x100]
- LRU(Least Recently Used)는 가장 최근에 참조된 데이터가 앞으로도 참조될 가능성이 높고, 오래된 데이터는 앞으로도 참조되지 않을 가능성이 높다는 주장이다.
보통 이런 문제에서 가장 표준적으로 생각하게 되는 접근으로 내 생각에 딱히 반박할 거리가 잘 생각이 나지 않는다.
구현에 있어서도 Linked List를 이용한다면 비교적 간단할 것이다.
buffer = [x1, x2, ..., x100]
def access(page, task):
if page not in buffer and full(buffer):
pop_back(buffer)
load(page) # push_front
task(page)
...
access(y, task)
# buffer = [y, x1, x2, ..., x99]
InnoDB의 개량 LRU 알고리즘
앞서 말한 얘기의 결론으로 대부분의 RDBMS는 메모리 관리를 위해 LRU 알고리즘을 사용하는 이유를 알아보았다.
이제 잠깐 실제 적용 사례인 MySQL InnoDB의 LRU 알고리즘에 대해 알아볼 것인데,
실제 시스템에서 얼마나 고도화된 전략을 사용하는지 그 아이디어와 발상에 대해 배우는 차원으로 보도록 하자.
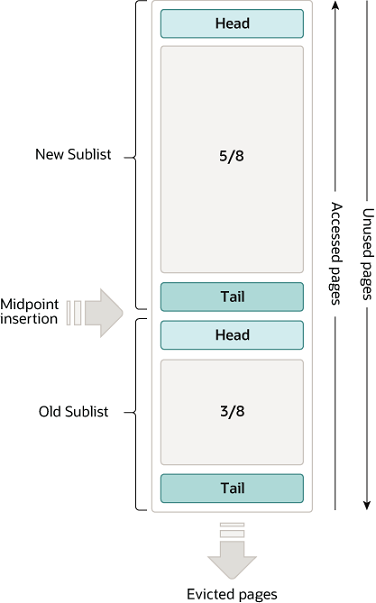
[InnoDB Buffer Pool]
InnoDB 버퍼풀은 LRU를 위한 Linked List의 개량형으로
이번에는 리스트를 두 개의 구역으로 분리한다.
하나는 최근에 참조된된 페이지를 위한 new sublist.
다른 하나는 최근에 참조되지 않고 있는 페이지를 위한 old sublist.
즉, 기존 LRU 리스트에서 특정 지점(midpoint라고 지칭한다)를 기준으로
다시 한 번 리스트를 분리한 것이다.
이에 따라 데이터(페이지)를 리스트에 삽입하는 방식이 달라지게 된다.
먼저 다음과 같이 리스트가 구성된 상태라고 가정하자.
new_list = [x1, x2, ..., x70]
old_list = [x71, x72, ..., x100]
buffer_pool = new_list + old_list
이제 만약 LRU 리스트에 존재하지 않는 페이지 y에 접근한다면?
다음과 같이 우선 old list에 y를 추가하고 oldlist의 꼬리인 x100이 evict된다.
def access(page):
if page not in buffer_pool:
evict(oldlist)
# 마지막 원소를 제거
push(oldlist, page)
# old list의 head(midpoint)에 페이지를 추가
access(y)
# buffer_pool = [x1, x2, ..., x70] + [y, x71, x72, ..., x99]
그렇다면 버퍼풀에 존재하는 페이지에 재접근하는 경우는 어떻게 될까?
newlist나 oldlist건 어느 곳의 head로 옮겨주긴 한다.
이 때 oldlist의 경우 몇 번이나 접근했는지 횟수를 카운팅을 하는데,
만약 일정 임계치를 넘길 경우 이를 newlist로 옮겨준다.
def access(page):
if page not in buffer_pool:
evict(oldlist)
# 마지막 원소를 제거
push(oldlist, page)
# old list의 head(midpoint)에 페이지를 추가
elif page in new_list:
# new list의 페이지는 그대로 LRU 알고리즘을 수행한다.
pop(new_list, page)
push(new_list, page)
elif page in old_list:
pop(old_list, page)
if page.access_time > old_blocks_time:
# 일정 임계치보다 접근횟수가 높을 경우 이를 new list로 옮겨준다.
push(new_list, page)
else:
# 아직 임계치를 넘지 못하면 old list를 유지
push(old_list, page)
...
page.access_time += 1
access(x3)
# buffer_pool = [x3, x1, x2, ..., x70] + [y, x71, x72, ..., x99]
access(x71)
# 접근횟수가 충분히 많을 경우
# buffer_pool = [x71, x1, x2, ..., x69] + [x70, y, x72, ..., x99]
왜 이런 방식을??
굳이 이런 방식을 이용하는 이유는 물론 자주 사용되는 데이터를 더 효과적으로
구분하기 위함이다.
그 말인 즉슨 기본 LRU 방식을 사용했을 때 어떤 문제가 있었다는 것이다.
도대체 무엇이었을까?
정답은 Table Scan 작업이다.
Table Scan은 테이블 전체에 접근하는 작업으로 보통
dump 작업이나 where 절이 명시되지 않은 select 명령어에서 발생한다.
이러한 Full Table Scan이 일어나게 되면 대량의 데이터 페이지에 순차적으로 접근하게 되는데
이러한 페이지 접근은 사실상 Buffer Pool을 초기화하는 상황을 만들어버린다.
그렇다고 이런 쿼리가 동시적으로 계속 발생하는 작업은 아니기 때문에
한동안은 다시 히트율이 높은 페이지가 로딩되는 과정에서 시스템 지연이 발생할 위험이 생긴다.
따라서 LRU 리스트를 두 개로 나누어 몇 번 접근되고 마는 데이터는 old list에 적재하고
이전까지 계속 접근되고 앞으로도 접근될 확률이 높은 페이지를 보호하기 위한 대책을 세운 것이라 이해하면 될 것이다.